| Teil 15 : Datenstrukturen |
Bisher hatten wir uns damit beschäftigt, welche Befehle uns C an
die Hand gibt, um unsere Probleme zu lösen. Mittels des struct
lernten wir die Möglichkeit kennen, wie man aus den einfachen Datentypen
Strukturen bildet und diese für sich nutzt. In diesem Kapitel werden
wir uns mit einigen Strukturen befassen und deren Vorzüge kennenlernen.
Es wird sehr viel mit Zeigern gearbeitet, da diese dynamische Strukturen
ermöglichen. Daher ist es sinnvoll, sich das
Kapitel über Zeiger nochmals anzuschauen, sowie das
Kapitel über Speicherbelegung und -freigabe. Bei den Beispielprogrammen
sind die Strukturen in der Datei struktur.h enthalten, die Module
in struktur.c ,welche am Ende des Kapitels
heruntergeladen werden können.
| dynamische Listen |
Bisher hatte man das Problem bei Feldern, das man eine starre Größe
hatte und somit waren.diese unflexibel. Wenn man nun eindimensionale Felder
hatte, so konnte man sie auch als Listen auffassen, wo ein Feldelement
nach dem anderen aufgereiht war, an einer Perlenkette sozusagen. Mit den
folgenden Listentypen werden wir uns eine Basis für Algorithmen schaffen,
die das Leben vereinfachen.
| einfachverkettete Listen |
Nun lernen wir eine Möglichkeit kennen, wie wir Listen erstellen
können, die man in der Größe ändern kann. In der Regel
benutzt man für einfachverkettete Listen folgende Struktur, in der
wir Beispielweise eine Variable vom Typ double speichern wollen.
Die Struktur nennen wir evListe , was an den Namen einer einfachverketteten
Liste erinnern soll. Wie wir sehen ist das zweite Element in der Struktur
ein Zeiger auf die Struktur selbst ist. Das funktioniert in dem Sinne,
das von einem Element des Typs der Struktur auf ein zweites, oder sich
selbst gezeigt werden kann. Der Name next ( engl. für nächster
) bezieht sich auf die Tatsache, das der Zeiger auf die nächste Struktur
zeigt. Ich habe hier bewuß die englischen Bezeichnungen gewählt,
da in der Regel in Fachbüchern und anderen Publikationen Zeiger auf
Daten englisch gehalten sind.
| struct evListe
{ double Element;} *ListenStart; |
Mit dieser Datenstruktur kann man nun elegant Datenelemente anordnen, löschen und einfügen. Schauen uns das Prinzip etwas näher an. In den folgenden Betrachtungen ist der Start der Liste mit einem S gekennzeichnet und das Ende mit einem E markiert.Das Ende werden wir in unseren Listen durch einen NULL-Zeiger realisieren, also einen Zeiger, der den Wert NULL (aus der Initialisierung) besitzt. Wenn wir also eine leere Liste haben, so haben wir ein Startelement, was aber gleich wieder auf eine Endmarkierung ( = NULL ) verweist.
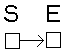
leere Liste
Haben wir nun eine Liste mit einem Eintrag, so zeigt das Startelement auf den ersten Wert. Durch den Zeiger auf das nächste Element, in der Struktur durch struct evListe *next , weißt dieses Element auf unsere Endmarkierung hin.
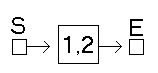
Der Vorteil dieser Konstruktion ist das Einfügen. Wollen wir nun ein neues Element in die Liste einfügen, so lassen wir den Zeiger des Vorgängers nun auf das neue Element zeigen und den Zeiger des neuen Elementes auf den Nachfolger. So schiebt man das Element quasi zwischen zwei Elemente, welche nun die Vorgänger, bzw. Nachfolger des neuen Elementes sind.
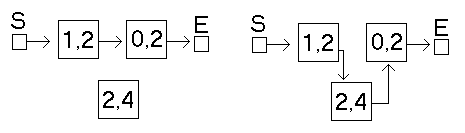
Einfügen in die Liste
Schauen wir uns die neue Verkettung an, so sehen wir, das wir das alte Feld vergrößerten, in dem wir ein neues Element einschoben. Wie wir uns denken können, kann dies an beliebiger Stelle geschehen. Auf diese Weise kann man leicht Zahlenwerte aufsteigenderweise einordnen und erhält so eine vorsortierte Liste. Dazu jedoch später mehr.
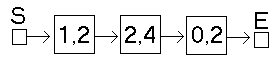
Genauso einfach läßt sich dann ein Element entfernen. Man läßt den Zeiger des Vorgängers auf den Nachfolger des zu löschenden Elements zeigen und umgeht somit das zu löschende Element. Da das Element aber immer noch sich im Speicher befindet und wertvollen Speicherplatz verschwendet, sollte es nachher aus dem Speicher entfernt werden. ( z.B. mit free )
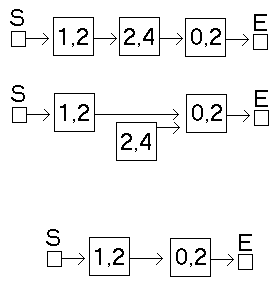
Löschen aus der Liste
Wenden wir unsere Theorie einmal in der Praxis an und schreiben ein
erstes Programm um eine Liste mit einem Element zu erzeugen. Zum testen,
ob auch alles glatt lief, wollen wir es natürlich auch wieder auslesen
und auf den Bildschirm schreiben. Wir erzeugen also einen Zeiger auf das
Anfangselement unserer Liste. Da Zeiger generell uninitialisiert sind,
sollten wir uns daran gewöhnen sie mit NULL zu initialisieren.
Dies können wir später zum Abfragen der Liste benutzen. Da wir
aber noch keinen Platz im Speicher reserviert haben, tun wir das nun mit
malloc
und schreiben dort den Wert unseres ersten Elements in der Liste, welches
wir anschließend wieder ausgeben. Am Ende, geben wir den Speicher
wieder frei mit free.
| #include <stdio.h>
#include <stdlib.h> #include "struktur.h" void main (void)
struct evListe *Liste = NULL;} |
Mit zwei Listenelementen geht es analog zu obigem Verfahren.
| #include <stdio.h>
#include <stdlib.h> #include "struktur.h" void main (void)
struct evListe *ListeStart = NULL;} |
Ansich ist es nun etwas umständlich jedesmal alle Elemente von
Hand zu löschen. Wir schreiben also Module, mit deren Hilfe man in
eine Liste Elemente schreiben und löschen kann. Damit wir uns Schreibarbeit
sparen, benutzen wir eine Typendefinition für unseren neuen Typ und
nennen sie EVL , wie einfachverkettete Liste.
| typedef struct evListe EVL; |
Beschäftigen wir uns als erstes mit dem Einfügen. Hierbei
gehen wir immer davon aus, das der Listenzeiger mit NULL initialisiert
wurde. Wir belegen zuerst eine Speicherstelle mit einer Variablen unseres
Typs EVL und setzen den Wert und lassen den Zeiger auf das Folgeglied
auf den alten Listenstart zeigen. Schlug das Speicheranfordern fehl, so
geben wir wieder den alten Listenstart zurück. Lief alles wie gewünscht,
so geben wir den Zeiger des neuen Listenstarts an, an dem nun unser neuer
Wert liegt.
| EVL *EvlEinsetzen (EVL *Start, double Wert)
{ /* einzufügendes Element */} |
Wie wir sahen setzten wir am Anfang stets die neuen Listenelemente ein. Schematisch sieht das wie folgt aus.
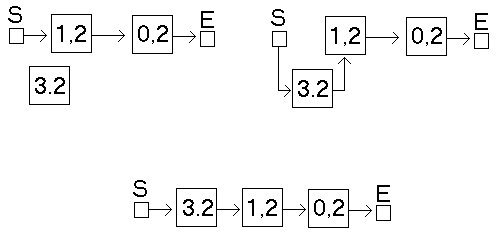
Einfügen eines Listenelements
Prinzipiell geht das Löschen auf die gleiche Art, nur das wir hier das Problem haben uns den Vorgänger zu merken. Wollen wir uns also nun eines Listenelementes entledigen, so funkioniert es nach dem bereits oben erwähnten Schema. Der Vorgänger zeigt auf den Nachfolger des zu löschenden Elements und danach wird der Speicher des Elements mittels free wieder freigegeben.
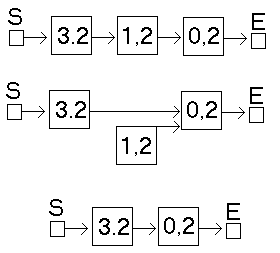
Löschen eines Listenelements
Beim löschen haben wir einige Sodnerfälle zu beachten. Was
passiert, wenn Sonderfälle vorliegen ? Wie wir schon sahen, benötigen
wir eine Hilfszeiger temp, der an den Listenelementen entlang geführt
werden soll, einen Hilfszeiger davor , der auf das vorhergehende
Listenelement zeigt und einen Index, in dem wir übergeben,
das wievielte Element gelöscht werden soll. Doch zuerst sollten wir
einige Sonderfälle abprüfen. Wenn der Listenzeiger noch keinen
Eintrag enthält ist dessen Wert
NULL und somit können
wir nichts löschen. Wenn das Anfangselement gelöscht werden soll
(Index = 0) , brauchen wir nur das Folgeelement zurückgeben und können
den Speicher des Startelements gleich löschen. Wenn wir die Liste
entlang gehen, um den betreffenden Index zu finden, so kann es passieren,
das vor dem Index das Listenende erreicht wurde, also kein Listenelement
unter dem gesuchten Index existiert. In dem Fall geben wir den Zeiger des
Startelements zurück, ohne etwas an der Liste zu verändern. Wenn
alles bis hierher glatt verlief, dann ist der Index auf 0 heruntergezählt
worden und das Element unter dem Index ist gefunden, der Zeiger von temp
verweist auf das Element und der Zeiger davor verweist auf dessen
Vorgänger. Nun lassen wir den Zeiger des Vorgängers auf den Nachfolger
des zu löschenden Listenelementes zeigen und geben danach dessen Speicher
frei. Somit ist das Element aus der Liste entfernt und aus dem Speicher
gelöscht.
| EVL *EvlLoeschen (EVL *Start, int Index)
{ EVL *temp, *davor;} |
Damit wir ein wenig mit unseren Listen experimentieren können,
wollen wir sie natürlich auch anzeigen lassen. Dazu schreiben wir
ein Programm welches die Listenelemente nacheinander ausgibt.Dazu schreiben
wir folgende kleine Routine, welche am Anfang prüft, ob Elemente vorhanden
sind. Wenn ja, so werden sie nacheinander ausgegeben. Nach jedem Ausgeben
eines Elementes wird der Zeiger auf den Nachfolger gesetzt, bis dieser
NULL
ist und somit unsere Abbruchbedingung erreicht ist.
| void evlZeigen (EVL *Start)
{ EVL *temp; if (Start == NULL) return;} |
Unsere Liste testen wir sofort aus, indem wir ein kleines Testprogramm
schreiben. Hier werden die Module in struktur.c und die Definitionen
und Prototypen in struktur.h . Diese Dateien kann man natürlich
auch herunterladen.
| #include <stdio.h>
#include <stdlib.h> #include "struktur.h" void main (void)
EVL *Liste=NULL;} |
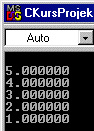
Wie wir sehen, werden alle neuen Elemente am Kopf der Liste angehängt.
| mehrfach verkettete Listen |
Einfachverkettete Listen haben den Nachteil, man kann schwer an ein
Vorgängerelement gelangen. Um dieser Miesere zu entgehen, jedesmal
die Liste neu abzuwandern, um ein bestimmtes Vorgängerelement zu finden,
erweitern wir unsere einfachverketteten Listen um einen Zeiger auf den
Vorgänger. Der Bezeichner previous ( engl. für davor )
soll andeuten, das dieser auf den Vorgänger zeigt und next
, wie zuvor, auf den Nachfolger.
| struct mvListe
{ double Element;} *ListenStart; |
Wie zuvor werden wir diese Struktur einen eigenen Typennamen geben.
Wir nennen sie MVL , für mehrfachverkettete Liste.
| typedef struct mvListe MVL; |
Mit dieser Struktur kann man nun den entscheidenden Vorteil gegenüber einfach verketteten leicht erkennen. Von einem Element kann man nun ohne Probleme zum Vorgänger und Nachfolger gehen und wir müssennicht mehr die komplette Liste von vorne durchkämmen.
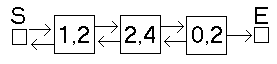
doppeltverkettete Liste
Das löschen und einfügen erfolgt hier analog zu dem Verfahren
bei einfachverketteten Listen. Es werden die Zeiger von Vorgänger
und Nachfolger geändert.
| Stack |
Wie ein Stack arbeitet haben wir schon im Kapitel über Rekursion kennengelernt. Nun wollen wir einen Stack selber programmieren. Bei einem Stack können wir jeweils nur das oberste, hier das erste Element, auf den Stack packen (push) und entfernen (pop), wobei das entfernen dem lesen gleichkommt, bzw. den gespeicherten Wert ausgibt. Wenn der Stack leer ist, bekommen ist der Zeiger auf die Liste NULL. Der Stack ist von der Speicherart her ein sogenannter LIFO-Typ ( Last-In-First-Out ) , was auf deutsch soviel heißt wie: Was als letztes reingesteckt wurde, bekommt man auch als erstes heraus.
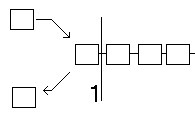
Stack
Im Prinzip können wir einen Stack mit den Mitteln realisieren,
die wir schon bei den einfachverketteten Listen angewendet hatten. Das
Modul zum Daten anhängen können wir unverändert lassen und
ebenso das Modul zum löschen eines Elements, wir brauchen eh nur das
0-te (also das oberste) Element zu löschen. Wir modifizieren also
nur leicht das Modul zum ausgeben, da wir jeweils nur einen Wert, den obersten,
auslesen wollen.Unsere Module sehen also wie folgt aus.
| /* Legt einen Wert auf den Stack */
EVL *Push (EVL *Stack, double Wert) { return EvlEinsetzen (Stack, Wert);} /* Entnimmt den Wert vom Stack und gibt ihn aus */
if (Stack == NULL) return NULL;} |
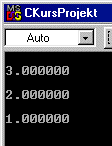
Diese Module probieren wir mit einem Testprogramm aus und lassen uns
den erzeugten Stack anzeigen. Wir sehen die Werte vom obersten, dem zuletzt
eingegebenen, zum untersten, dem zuerst eingegebenen, Wert hin sortiert.
| #include <stdio.h>
#include <stdlib.h> #include "struktur.h" void main (void)
EVL *Stack = NULL;} |
Zur Übung kann man sich überlegen, wie ein Stack für
Zeichen aussehen müßte. Bei Annäherungsschwierigkeiten
an das Thema, sollte man versuchen Schritt für Schritt nachzuvollziehen,
welche Werte gerade auf dem Stack in welcher Reihenfolge liegen. Eventuell
ist es hilfreich, das Kapitel zum Thema Rekursion
sich noch einmal anzuschauen.
| Queue |
Eine Queue, oder auch Schlange genannt, ist von der Struktur ähnlich dem Stack, nur mit dem Unterschied, das der Speicher vom Typ her ein FIFO ( First In - First Out ) ist, was bedeutet, das die Daten die als erstes hineingehen, als erste herauskommen. Ähnlich arbeiten auch Pufferspeicher im Computer, die die Daten in der gleichen Reihenfolge wieder ausgeben, in der sie empfangen wurden.
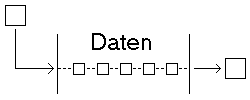
Queue
Wir benutzen wieder unsere Listen, um eine Queue zu erzeugen. Bei einer
Queue sind wieder zwei Worte im generellen Gebrauch, einmal für das
Schreiben (put) und das Lesen (get).Das Schreiben in die
Queue werden wir wieder über die bereits benutzte Funktion der einfachverketteten
Listen realisieren ( EvlEinsetzen ). Zum Lesen müssen wir jedoch
ans Ende der Liste und die Daten von dort ausgeben und anschließend
löschen. Beide Funktionen können wie folgt realisiert werden.Ist
die Liste leer, so wird NULL zurückgegeben, bzw. keine Daten
auf dem Bildschirm.
| /* Legt einen Wert auf die Queue */
EVL *Put (EVL *Queue, double Wert) { return EvlEinsetzen (Queue, Wert);} /* Entnimmt den Wert von der Queue und gibt ihn aus */
/* Hier wird die Position des letzten Elements gespeichert */} |
Die Get-Funktion könnte man noch beschleunigen und eleganter schreiben, indem man einen festen Zeiger auf das Ende der Queue hat. Schreiben wir nun ein Testprogramm um zu sehen, ob auch die Daten in der Reihenfolge gelesen werden, in der sie hineingeschrieben wurden. Im folgenden Beispiel werden nacheinander die Daten 1, 2, 3 und 4 in die Queue gesetzt (put) und danach werden die Daten aus der Queue geholt (get) und ausgegeben.
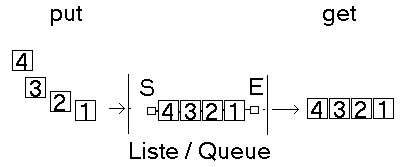
Funktionsweise einer Queue
| #include <stdio.h>
#include <stdlib.h> #include "struktur.h" void main (void)
EVL *Queue = NULL;} |
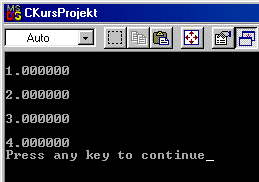
Wie wir sehen können, werden die Zahlen in exakt der Reihenfolge
ausgegeben, in der sie auch eingegeben werden.
| Bäume |
Die bisherigen Strukturen basierten auf eindimensionalen Feldern. Nun werden wir uns mit Strukturen befassen, die in die Tiefe gehen; mit sogenannten Bäumen. Der Nachteil bei bisherigen Verfahren war, das man sich immer nur nach vorne und hinten entlang einer Liste bewegen konnte. Das Thema Bäume ist aber so komplex, das man Bücher füllen könnte, daher soll es nur dazu dienen einen kleinen Vorgeschmack auf das Thema zu bekommen. Im folgenden wird auch auf komplexe Beweise verzichtet.
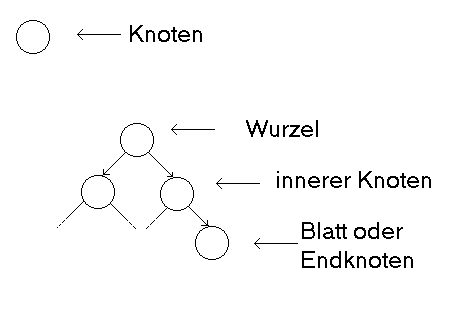
Knoten bezeichnen wir in der Regel allgemein einzelne Elemente eines
Baumes, die Daten enthalten, sie werden auch als Schlüssel bezeichnet..
Dazu gibt es einige spezielle Arten von Knoten. Der Knoten, an dem der
ganze Baum hängt, wird als Wurzel oder Wurzelknoten bezeichnet. Verbindungen
zwischen Knoten nennt man Pfade. Die Knoten, zu denen Pfade hinführen
und wieder welche wegführen nennt man innere Knoten, da sie in den
Baum eingebettet sind. Die Knoten, die ganz unten hängen und von denen
keine neuen Pfade wegführen, nennt man Blätter oder Endknoten.
Bäume sind also Konstrukte, bei denen jeder Knoten eine Folge von
Nachfolgeknoten haben kann.
| binäre Bäume |
Binäre Bäume sind Bäume, bei denen jeder Knoten maximal
2 Nachfolger hat. Diese werden in der Regel als rechter und linker Nachfolger
(auch Tochter oder Sohn genannt) bezeichnet. Wenn wir nun eine Struktur
für einen Knoten eines binären Baumes (BKnoten) bilden,
so enthält er einmal den Schlüssel (key), der die Daten
des Knoten enthält und zwei Zeiger auf den rechten und linken Nachfolger,
welche mit l (links) und r (rechts) gekennzeichnet sind.
| struct BKnoten
{ char key;} |
Das ist die geläufigste Variante. Zusätzlich gibt es eine
Variante, die den übergeoredneten Knoten durch einen Zeiger p
(parent) verwaltet. Diese Variante ist sehr hilfreich, wenn man
mit Modulen arbeitet, wo beispielsweise Knoten mit übergeordneten
Knoten vertauscht werden sollen. Diese Variante wird auch in unserer Headerdatei
struktur.h
verwendet.
| struct BKnoten
{ char key;} |
Zur einfacheren Handhabe werden wir noch eine Typendefinition durchführen
um so unseren neuen Typ Knoten zu definieren. Wie zuvor werden wir NULL
als Abbruchbedingung festlegen, als sogenannten Terminator.
| typedef struct BKnoten Knoten; |
In einem binären Baum hat jeder Knoten einen Vorgänger, bis
auf den Wurzelknoten. Einen Baum kann man in Ebenen einteilen. Ebene 0
ist der Wurzelknoten, Ebene 1 sind die Nachfolger des Wurzelknoten, Ebene
2 sind die Nachfolger aller Knoten von Ebene 1 und so weiter. Natürlich
will man nun die Möglichkeit habe alle Knoten eines Baumes einmal
zu besuchen. In der Informatik nennt man das traversieren. Mit der Baumstruktur
ist das sehr einfach.
| void besuchen (Knoten *Baum)
{ if (Baum == NULL) return;} |
Sieht nicht viel aus. Was macht das Modul nun ? Ist der besuchte Knoten NULL , so ist es das Modul von einem Blatt aufgerufen worden und geht zurück zum aufrufenden Knoten. Dieses Prinzip beruht auf der sogenannten Tiefensuche, d.h. es wird solange es geht in den tiefsten Ebenen nachgeschaut. Das vorgestellte Modul bereist, solange es geht, alle linksseitigen Tochterknoten und danach die rechtsseitigen. Dadurch geht dieses Modul sehr schnell in die Tiefe des Baumes. Nachdem nun das Aufrufen des linksseitigen Knoten beendet ist, wird der rechtsseitige aufgerufen. An dieser Stelle befindet sich das Modul sozusagen am untersten linksseitigen Blatt des Baumes.
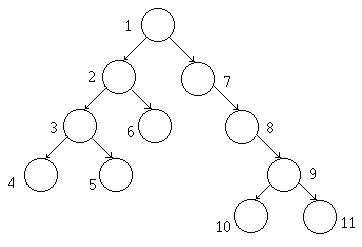
Tiefensuche
Es wurden hier die Reihenfolge der Besuche einmal aufgezeichnet. Der erste Übergabeparameter ist hier die Wurzel und hat natürlich die Numemr 1. Die Folgenummern verdeutlichen hier, wie die Tiefensuche verläuft. Dieses Prinzip werden wir etwas abgewandelt bei Bäumen verwenden, die wir automatisch vorsortieren.
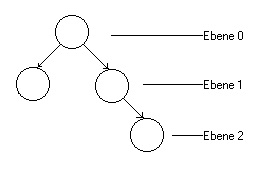
voller Baum
Ein binärer Baum heißt voll, wenn alle Ebenen, bis auf die letzte, gefüllt sind, d.h. die letzte Ebene kann auch leer sein. Wenn wir also unseren Baum in der oberen Grafik betrachten, so ist er voll. Ein binärer Baum heißt komplett, wenn er linksbündig voll ist, das heißt auf der unteren Ebene alle linksbündigen Knoten besetzt sind. Der obere Baum ist also ein voller, aber kein kompletter Baum. Sehen wir uns einmal einen kompletten Baum an.
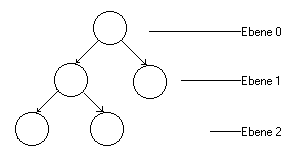
kompletter Baum
Ebene 0 ist voll, Ebene 1 ist voll und Ebene 2 ist linksbündig voll. Damit ist dieser Baum ein kompletter Baum. Wie wir schon erwähnten, werden Bäume zur Datenrepresentation benutz, d.h. jeder Knoten enthält einen Datensatz. Im Folgenden werden wir als Daten Zeichen in den Knoten benutzen. In der Regel werden Bäume durch die bereits kennengelernte Datenstruktur dargestellt. Komplette Bäume haben den Vorteil, das man sie relativ einfach in Form einer Liste, bzw. einem Feld darstellen kann.
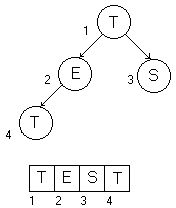
Baum als Liste
Wir nennen das Feld F und die Indizes des Feldes i . Wie man am Baum sieht, sind die Nachfolger von Knoten 1 die Knoten 2 und 3 , von Knoten 2 ist der Nachfolger der Knoten 4 (und so es ihn geben würde Knoten 5). Es wird erst eine Ebene aufgefüllt, bevor ein Element in der nächsten Ebene angehängt wird. Dazu überprüft der oberste Knoten, ob rechts und links noch Knoten existieren, wenn nicht, so wird der neue Knoten eingefügt. Ansonsten wird die Abfrage im linken und rechten Tochterknoten fortgeführt.
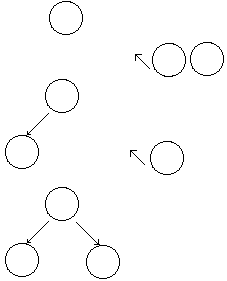
Einfügen in einen Baum
Dabei gelten folgende Regeln, die einem sehr elegant die einzelnen Elemente
einer Liste einem eindeutigen Knoten zuordnen lassen.
| Die Nachfolger von F[i] sind F[2i] und F[2i + 1] |
| Der Vorgänger von F[i] ist F[i / 2] |
Der Vorgänger wird hier durch eine ganzzahlige Division ermittelt.
( 1/2 = 0 ; 2/2 = 1 ; 3/2 = 1 ; 4/2 = 2 ; u.s.w. ). Bei 0 gehen wir
davon aus, das es keinen Vorgänger gibt. Kommen wir nun noch einmal
auf das Modul zurück, welches den Baum traversierte, das heißt,
das jeden Knoten einmal besuchte. Dort hatten wir eine sogenannte Tiefensuche.
Wollen wir nun eine Breitensuche ermöglichen, also ein Besuchsschema,
welches solange es geht in den höchsten Ebenen bleibt. Dies ist relativ
einfach mit einer Liste zu realisieren. Haben wir den Baum in eine Liste
umgewandelt, so können wir mit foglendem Modul eine Breitensuche durchführen.
| void besuchenL (EVL *Baum)
{ while (Baum != NULL)} |
Durch den Listenaufbau ist es sozusagen schon vorgegeben, das man nur noch die Liste ablaufen muß. Die einzige Vorbedingung ist, das der Baum als kompletter Baum vorliegt. Wie folgt wird der Baum dann durchsucht. Die Zahlen geben die Besuchsreihenfolge wieder.
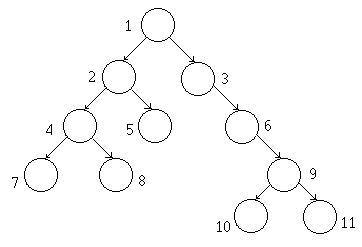
Breitensuche
Moment, wird einer treffend sagen, der abgebildete Baum ist doch nicht komplett, wie geht man denn bei solchen vor ? Im Prinzip wird er als kompletter Baum abgebildet, wobei den Werten der eigentlich nicht vorhandenen Knoten eine definierter Wert, z.B. NULL , zugewiesen wird. Dadurch hätten wir den oberen, nicht kompletten Baum als den unteren Abgebildet, wobei die farblich markierten den Schlüssel NULL besitzen, in unseren Sinne also nicht existieren. Ein Nachteil ist hierbei offensichtlich: die Liste wird umso länger, je mehr Löcher es gibt.
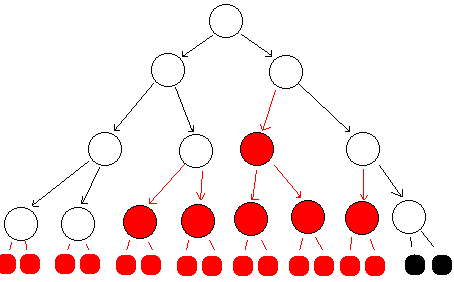
Die rot markierten Pfade und Knoten sind die Löcher und haben als
Wert mit NULL , die schwarzen Elemente sind die Nutzdaten des Ursprungsbaumes.
Wie man sieht, ist eine daraus enstandene Liste um einiges größer,
als der Ursprungsbaum an sich groß ist. Auch so kann man wertvollen
Speicher vergeuden :-)
| Heap |
Der Begriff des Heaps ist im Bereich der Datenstrukturen etwas anderes
als der Heap, den Programmierer kennen. Dort ist ein Heap ein Speicherbereich,
den der Programmierer anfordern kann (z.B. mit malloc). Bei den
Datenstrukturen ist ein Heap, oder auch Halde genannt, eine Reihung, d.h.
eine Liste, in der kein Knoten einen größeren Schlüssel
als der Vorgänger hat. Bei dem Vergleich zu den Vorgängern wird
sich immer auf die Baumstruktur berufen. Daher ist eine Halde in diesem
Sinn immer vorsortiert, muß es in der Liste aber nicht sein. Würden
wir im Beispielbaum die Elemente der Indizes 2 und 3 vertauschen, würden
wir einen Heap erzeugt haben, aber keine vorsortierte Liste.
|
kein Heap |
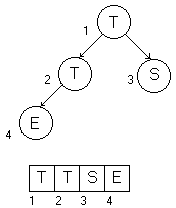
Heap |
Vergleichen wir beide oberen Bäume, ob die Heapbedingung erfüllt
ist. Auf der linken Seite wird die Heapbedingung nicht erfüllt, da
e
< t ist ( Knoten 2 < Knoten 4 ). Vertauschen wir diese beiden,
so ist die Heapbedingung erfüllt und wir erhalten den Baum auf der
rechten Seite. Wie man sieht, kann man einen Baum in eine Halde überführen,
in dem man solange einen Vorgänger mit seinem Nachfolger vertauscht,
solange dieser die Heapbedingung verletzen.
| die Datei struktur.h und struktur.c |
In den Beispielprogrammen wurde eine Headerdatei struktur.h eingebunden,
die alle besprochenen Beispielstrukturen enthält. Wie das einbinden
erfolgt, kann man im Kapitel
über den Precompiler nochmals nachlesen.In der Datei struktur.c
enthält
die Module zu den entsprechenden Datentypen.

struktur.h & struktur.c
| ...das Obligatorische |
Autor: Sebastian Cyris PCDBascht@aol.com
Dieser C-Kurs dient nur zu Lehrzwecken! Eine Vervielfältigung ist ohne vorherige Absprache mit dem Autor verboten! Die verwendete Software unterliegt der GPL und unterliegt der Software beiliegenden Bestimmungen zu deren Nutzung! Jede weitere Lizenzbestimmung die der benutzten Software beiliegt, ist zu beachten!Bisher hatten wir uns damit beschäftigt,